Why strong data foundations are the real prerequisite for scalable AI
If you regard data preparation as an afterthought, your AI strategy is building a skyscraper on a swamp
Add bookmarkListen to this content
Audio conversion provided by OpenAI


Artificial intelligence (AI) has officially taken center stage in every enterprise strategy conversation. From boardrooms to breakrooms, the promise of generative AI and autonomous agents is palpable.
Yet, despite the enthusiasm and massive investment, a quiet crisis is brewing: ‘pilot purgatory.’
Many organizations find themselves stuck running promising experiments that dazzle in the lab but fail to translate into durable business value when deployed. Leaders often blame the algorithms, the prompt engineering, or the lack of GPU availability.
However, in my experience architecting large-scale systems, the culprit is rarely the AI itself. A much more reliable determinant of AI success is the boring, unglamorous strength of the underlying data environment.
AI systems do not magically fix enterprise data realities, they exaggerate them. When data is siloed, inconsistent, or poorly governed, AI results become unreliable, hard to interpret, and dangerous to automate.
The central question for business leadership in 2026 is no longer if AI can deliver value, but whether the organization’s data ecosystem is mature enough to support AI in a dependable, repeatable manner.
Join the PEX Network community

Don't miss any news, updates or insider tips from PEX Network by getting them delivered to your inbox. Sign up to our newsletter and join our community of experts.
Learn MoreAI does not fix data problems – it amplifies them
A persistent myth in enterprise adoption is that sophisticated large language models (LLMs) can overcome imperfect data. There is a belief that the model is ‘smart enough’ to figure it out. The opposite is true: machine learning systems amplify biases, inconsistencies, and gaps that exist in their training data.
Consider a scenario where a company tries to deploy a ‘financial AI agent’ to automate reporting. If the sales data in the CRM doesn’t match the recognized revenue in the ERP system, the AI won’t resolve the conflict – it will confidently hallucinate a number or execute a flawed calculation based on the wrong source. Models trained on incomplete or conflicting sources often perform well in controlled sandboxes but fail catastrophically in production, leading to a rapid loss of stakeholder trust.
Industry research backs this up. Gartner reports that poor data quality costs the average organization US$12.9 million annually. AI initiatives are particularly sensitive to this cost because they rely heavily on historical patterns. If you regard data preparation as an afterthought, your AI strategy is building a skyscraper on a swamp.
Register for All Access: AI in PEX 2026!
What makes data truly AI-ready?
Big data is not the same as AI-ready data. We are moving past the era where volume was king. Today, readiness is defined by the foundational characteristics that determine whether models can be trusted to make decisions.
- Consistency: Does ‘customer churn’ mean the same thing to the marketing AI as it does to the finance AI? If your semantic layer is broken, your AI agents will fight each other.
- Timeliness: In an era of real-time decision-making, batch processing is often insufficient. Predictions must reflect current operating conditions, not last week’s database snapshot.
- Traceability and lineage: This is the supply chain of your data. When an AI generates an insight, can you trace exactly which data points fueled that conclusion? This transparency is the essential requirement for explainability and regulatory compliance.
Accessibility is just as critical. Data locked in legacy silos or ambiguous ownership structures constrains the insights AI can uncover. Organizations that succeed typically define common definitions and accountability models early, aligning data producers and consumers around shared standards before a single model is trained.
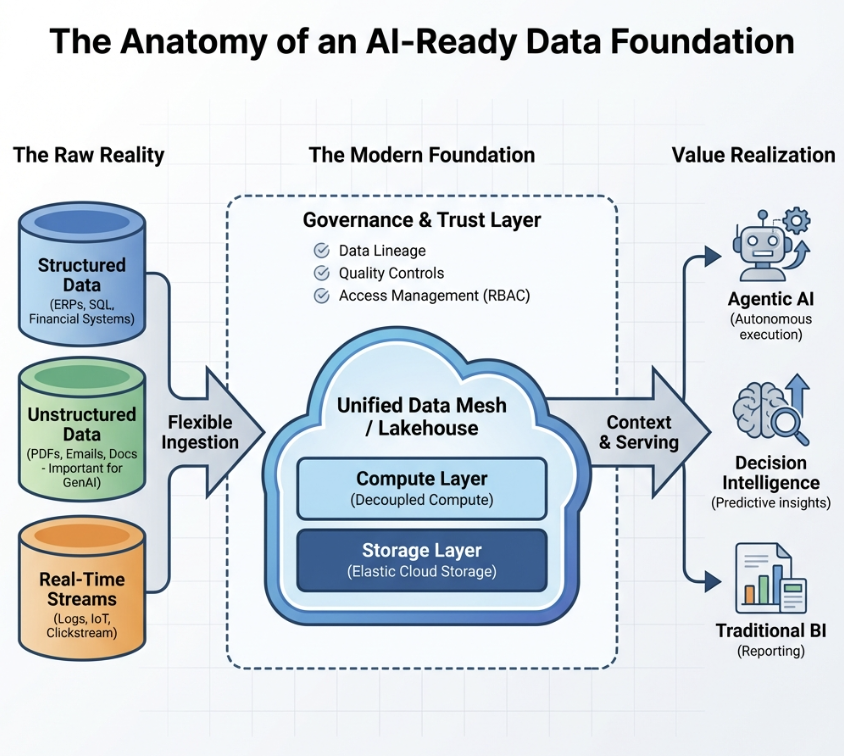
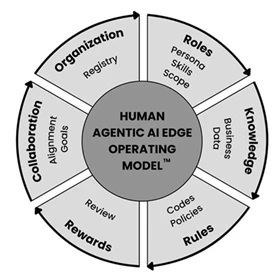
The transition from fragmented data silos to a governed, unified foundation is the critical architectural shift required to support scalable agentic AI. Diagram created by the author, Rahul Chawla.
Architecture matters – when aligned to purpose
Modern data architectures are the engine room of AI, especially in cloud-native enterprises. We need elastic compute and storage to accommodate the massive fluctuations of training and inference workloads. However, buying a modern cloud data warehouse is not a strategy in itself.
Flexible ingestion pipelines need to handle structured (SQL) and unstructured (PDFs, emails, logs) data simultaneously. This is the fuel for generative AI. Furthermore, architectures must allow for independent scaling of compute and storage to manage the exploding costs of AI (FinOps). Without these architectural levers, AI projects frequently stall due to latency bottlenecks or ballooning infrastructure bills.
McKinsey’s recent research highlights that organizations achieving sustained AI impact don’t just adopt technology; they align architectural decisions with business objectives. They build architectures that serve the use case, not just the IT department.
Join us at All Access: AI in Business Transformation 2026!
Governance as an enabler, not a blocker
Data governance is often viewed as a bureaucratic hurdle – a set of restrictions that slows down innovation. In the age of AI, we must reframe governance as ‘safety.’ Just as brakes allow a car to drive faster with confidence, good governance allows AI to scale responsibly.
Clear data ownership and stewardship create accountability. If an AI model fails, who owns the data that fed it? Standardized metrics ensure that AI-driven decisions are consistent across business units.
Embedding quality controls and managing access rights (RBAC) helps detect risks before they are consumed by models. This approach aligns with evolving regulatory expectations, such as the EU Artificial Intelligence Act, which emphasizes data provenance and bias mitigation. Organizations that integrate governance directly into their pipelines – treating ‘policy as code’ – are better positioned to foster trust and avoid costly compliance remediation later.
From experimentation to sustainable impact
Preparing data for machine learning requires a discipline different from traditional business intelligence reporting. Feature-ready data models need adequate historical depth and must ensure that training datasets match production reality. Neglecting data drift or early bias often results in models that degrade rapidly once deployed.
Success lies in transitioning from ‘hero projects’ to operational rigor. Automated pipelines, data observability, and continuous improvement cycles help keep AI systems reliable as business conditions change. In contrast, relying on manual data preparation or tolerating increasing ‘data debt’ ensures that your AI costs will surge while model effectiveness plummets.
Strong data foundations do not guarantee AI success, but weak ones virtually ensure failure. For enterprise leaders, investing in data quality, governance, and architecture is not a prerequisite to innovation – it is the mechanism by which innovation becomes sustainable.
All Access: BPM 2026

All Access: BPM 2026 from PEX Network will help professionals get an understanding of the latest developments in BPM, including how to identify and improve key processes, how to implement BPM technology, and how to measure the success of BPM initiatives.
Register Now